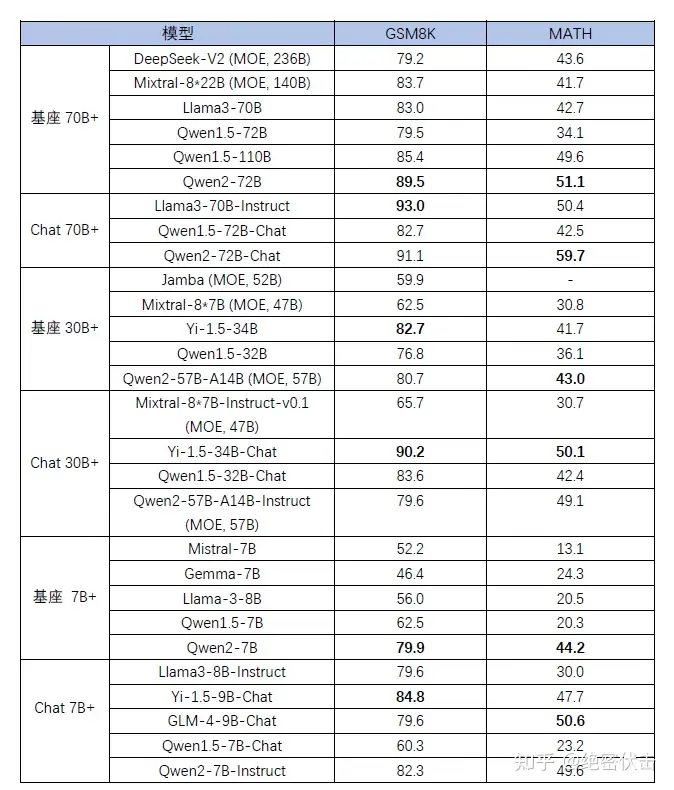
024年6月7日,阿里巴巴发布了最新的大模型 Qwen2,迎来了 Qwen 系列模型从 Qwen1.5 到 Qwen2 的重大升级。相比 Qwen1.5,Qwen2 在大规模模型实现了非常大幅度的效果提升。Qwen2-7B 的数学能力,甚至可以比肩 Qwen1.5-110B。
Qwen2 系列具备以下特点:
而紧随其后,在 2024 年 7 月 15 号,阿里发布了 Qwen2 的技术报告,今天我们就来解读下这份技术报告,看看 Qwen2 都做了哪些优化。
总的来说,这篇技术报告详细介绍了 Qwen2 系列,这是阿里巴巴集团 Qwen 团队最新推出的大型语言模型和大型多模态模型。
Qwen2 系列包含 5 个尺寸的预训练和指令微调模型,其中包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B。如下表所示:
| 模型 | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| 参数量 | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| 非Embedding参数量 | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
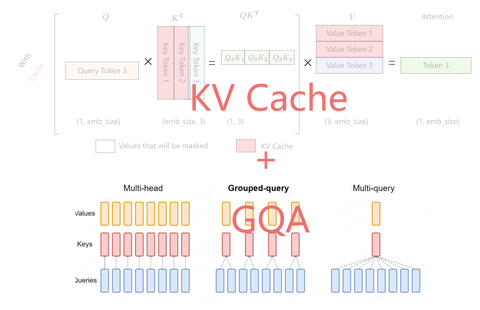
| GQA | True | True | True | True | True |
| Tie Embedding | True | True | False | False | False |
| 上下文长度 | 32K | 32K | 128K | 64K | 128K |
在 Qwen1.5 系列中,只有 32B 和 110B 的模型使用了 GQA。这一次,所有尺寸的模型都使用了 GQA,带来了推理加速和显存占用降低的优势。针对小模型,由于 embedding 参数量较大,Qwen2 使用了 tie embedding 的方法让输入和输出层共享参数,增加非 embedding 参数的占比。
上下文长度方面,所有的预训练模型均在 32K tokens 的数据上进行训练,并且其在 128K tokens 时依然能在PPL 评测中取得不错的表现。而在使用 YARN 这类方法时,Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 均实现了长达 128K tokens 上下文长度的支持。
下面具体介绍下具体细节。
Qwen2 BPE (Byte-Pair Encoding) 分词器,这种分词器在Qwen1.5中已经使用过。报告指出,BPE 具有高编码效率,这得益于它比其他替代方案有更好的压缩比率。这种高效的编码方式对于处理大型语言模型尤其重要,因为它可以减少模型训练和推理时的内存和计算需求。
tokenizer 的设计支持多语言能力,这对于 Qwen2 模型来说是一个关键特性,因为它需要能够处理包括英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语和越南语等在内的约30种语言。
报告提到所有模型使用了一个共有的词汇表,包含 151,643 个常规 tokens 和 3 个 control tokens (<|endoftext|>, <|im_start|>, <|im_end|>)。这种统一的词汇表有助于保持不同模型规模之间的一致性。
Qwen2 Dense 基于 Transformer 架构, 与前一代 Qwen 模型相比,Qwen2 Dense 在多个方面进行了改进,以提高模型的性能和效率。
GQA 的技术原理就不再具体展开了,感兴趣的可以看一下这篇文章:
这里介绍下 DCA (Dual Chunk Attention) 和 YARN (Yet Another Rescaling Method)。
分块注意力 DCA
DCA 是一种用于自然语言处理(NLP)任务的注意力机制,旨在高效处理长序列数据。DCA 通过将输入序列分块来减少计算复杂度,同时保留全局信息和局部信息。DCA 通常分为两个阶段:局部注意力和全局注意力。
在局部注意力阶段,输入序列被分成若干个块(chunks),每个块内的元素之间进行注意力计算。这种方式可以有效减少计算复杂度,因为注意力计算只在较小的块内进行。
在全局注意力阶段,每个块的表示被用来计算全局注意力。具体来说,每个块的表示可以是该块内所有元素的平均值或最大值。然后,这些块表示之间进行注意力计算,从而捕捉全局信息。
下面举一个具体例子。
假设我们有一个长度为12的输入序列:
全局注意力:对于每个块,我们计算一个全局表示。假设我们使用平均值作为块的表示:
DCA 通过分块的方式,将长序列的注意力计算分解为局部注意力和全局注意力两部分,从而有效减少计算复杂度,同时保留全局和局部信息。这种方法特别适用于处理长序列数据的任务,如长文本的自然语言处理。
YARN (Yet Another Rescaling Method)
YARN 用于重新调整注意力权重,以改善模型对不同长度序列的处理能力。它通过重新调整注意力权重,使得模型能够更好地处理长序列和短序列,避免在处理长序列时注意力权重过于分散,从而提升模型的整体表现。
YARN 的核心思想是对注意力权重进行重新缩放,以便在处理不同长度的序列时,注意力机制能够更有效地聚焦于重要的信息。具体来说,YARN 通过以下步骤实现这一目标:
下面举一个具体例子:
假设我们有一个序列长度为 5 的输入序列,模型计算得到的原始注意力权重矩阵为:
将缩放因子应用到原始注意力权重矩阵上:
Qwen2 MoE 模型的架构与 Qwen1.5-MoE-A2.7B 非常相似。作为原始 FFN 的替代,MoE FFN 由 n 个单独的FFN 组成,每个 FFN 充当一个专家。根据门控网络 G 分配的概率,每个 token 被定向到特定的 expert
专家粒度: MoE 与 Dense 之间的一个关键结构差异在于,MoE 层包含多个 FFN(前馈网络),每个 FFN 作为一个独立的专家。因此,从 Dense 架构过渡到 MoE 架构的一个直接策略是,将每个专家的参数设置为原始 Dense 模型中单个 FFN 的参数。例如,从 Mistral-7B 过渡到 Mixtral 8x7B,涉及一次激活八个专家中的一个。不同地,Qwen2 的模型采用了细粒度专家,同时创建规模更小的专家并激活更多的专家。在专家参数总数和激活参数数相等的情况下,细粒度专家提供了更丰富的专家组合。通过利用这些细粒度专家,Qwen2 MoE 促进了更多样化和动态的专家利用,从而提高了整体性能和适应性。
专家路由:设计专家路由机制对于提高 MoE 模型的性能至关重要。最近,出现了一个明显的趋势,即在 MoE 层中整合共享专家和特定路由专家。Qwen2 采用了这种方法,因为它便于在各种任务中应用共享专家,同时保留其他专家用于特定的路由场景选择性使用。引入共享专家和专用专家提供了一种更适应性强、效率更高的方法来开发MoE 路由机制。这点有点像 MMOE 结构。
专家初始化:给定指定的 expert 中间维度大小
关于 MoE 大模型的技术细节,可以参考下面链接:
模型配置
Qwen2 系列由 5 种大小的模型组成,分别是 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和Qwen2-72B。下表列出了超参数和重要信息,例如预训练 token 的数量。特别是,Qwen2-57B-A14B 是从Qwen2-7B 扩展而来的。值得注意的是,与 Qwen1.5 模型相比,Qwen2 模型展示了明显较低的 KV Heads。这一特性转化为减少的内存占用,特别是在长上下文推理任务中具有优势。
| 配置 | 0.5B | 1.5B | 7B | 72B | 57B-A14B |
|---|---|---|---|---|---|
| Hidden Size | 896 | 1,536 | 3,584 | 8,192 | 3,584 |
| # Layers | 24 | 28 | 28 | 80 | 28 |
| # Query Heads | 14 | 12 | 28 | 64 | 28 |
| # KV Heads | 2 | 2 | 4 | 8 | 4 |
| Head Size | 64 | 128 | 128 | 128 | 128 |
| Intermediate Size | 4,864 | 8,960 | 18,944 | 29,568 | 2,560 |
| # Routed Experts | 64 | ||||
| # Activated Experts | 8 | ||||
| # Shared Experts | 8 | ||||
| Embedding Tying | True | True | False | False | False |
| Vocabulary Size | 151,646 | 151,646 | 151,646 | 151,646 | 151,646 |
| # Trained Tokens | 12T | 7T | 7T | 7T | 4.5T |
在 Qwen2 的预训练中,主要重点放在完善数据集和研究有效处理扩展上下文长度的方法上。
Qwen2 模型的预训练涉及到开发一个新的、大规模的、高质量的多语言数据集。这个数据集相比之前 Qwen 和Qwen1.5 模型使用的数据集有了改进,增强了预训练数据的规模、质量和多样性,主要在以下几个关键领域:
质量增强:过滤算法已经通过额外的启发式和基于模型的方法进行了改进,包括使用 Qwen 模型来筛选出低质量的数据。此外,这些模型还被用来合成高质量的预训练数据。
数据扩展:与 Qwen1.5 相比,Qwen2 收集了更大量的高质量代码、数学和多语言数据,增强了模型在这些领域的能力。这个新数据集支持大约 30 种语言,如英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语和越南语。
分布改进:为了确保模型学习到类似于人类学习的分布,Qwen2 在小模型上进行实验,以优化来自不同来源和领域的数据混合。基于这些增强,预训练数据从 Qwen1.5 的 3 万亿个 token 扩展到了 7 万亿个 token。尝试进一步放宽质量阈值,产生了一个 12 万亿个 token 的数据集。然而,在这个数据集上训练的模型并没有显示出比 7 万亿个 token 更好的效果。除了 Qwen2-0.5B 之外,所有的 Qwen2 Dense 模型都是在这个超过 7 万亿个 token 的大规模数据集上进行预训练的。Qwen2-0.5B 是在使用 12 万亿个 token 的数据集上进行预训练的。MoE 模型根据提升再利用的原则,另外接收了 4.5 万亿个t oken 的预训练。与之前的 Qwen 模型类似,高质量的多任务指令数据被整合到 Qwen2 的预训练过程中,以增强上下文学习和指令跟随能力。
为了增强 Qwen2 处理长文本的能力,在预训练的最后阶段,Qwen2 将上下文长度从 4,096 个 token 增加到了32,768 个token。这一扩展通过引入大量高质量的长文本数据得到了补充。为了配合这些增强,Qwen2 将 RoPE的频率从 10,000 调整到了 1,000,000,以优化长上下文场景下的性能。为了充分利用模型的外推潜力,Qwen2 采用了 YARN 机制和双块注意力机制 DCA。这些策略使模型能够处理长达 131,072 个 token 的序列,同时保持高性能。
在进行了广泛的大规模预训练之后,Qwen2 进行了后训练阶段。这一过程对于提高其在包括编程、数学、逻辑推理、指令遵循和多语言理解在内的效果至关重要。此外,它确保了模型的生成与人类价值观相符合。与严重依赖大量人类监督的传统方法不同,Qwen2 的方法侧重于可扩展的对齐,最小化人类注释。具体来说,作者研究了获取高质量指令和偏好数据的方法,用于 SFT 和 RLHF,旨在在最大化数据质量和可靠性的同时,最小化对人类标记的需求。
后训练数据主要由两个组成部分构成:问题-答案数据集
训练数据的构建涉及两步过程:协作数据注释和自动化数据合成。首先,从大规模指令语料库中提取数据,从而得到广泛和多样化的高质量指令集合。这些指令被系统性地增强,以包含更大的复杂性。通过人工注释,获得目标响应
3.1.1 协作数据注释
自动提取:该过程首先应用 InsTag,一个开放式细粒度标记器,从小规模指令数据集中提取底层本体。
指令选择:每个带有标签的指令都根据标签多样性、语义丰富性、复杂性和意图完整性进行评估。基于这些标准,选择一组代表性的指令。
指令演化:为了丰富指令数据集,采用自我演化策略,促使 Qwen 模型向现有指令添加约束或要求,从而增加它们的复杂性,并确保数据集中不同难度级别的多样性。
人工注释:使用不同的生成策略和不同规模的 Qwen 模型获得对指令的多种响应。注释者根据他们的偏好对这些响应进行排名,确保最佳响应满足既定标准,产生示范和偏好数据。
3.1.2 自动化数据合成
拒绝采样:对于具有明确答案的数学类任务,应用拒绝采样来提高数据质量。大模型为每个指令生成多个响应,即推理路径。那些得出正确回答并且被模型认为是合理的路径将被保留,作为示范数据。通过对比正确和错误的路径来生成偏好数据。
执行反馈:对于编程任务,LLM 被用来生成解决方案和相关的测试用例。通过编译和执行这些解决方案来对抗测试用例,从而评估这些解决方案的有效性,由此创建示范数据和偏好数据。这种方法也适用于评估指令遵循。对于每个带有约束的指令,例如长度限制,LLM 被指派生成一个 Python 验证函数,以确保响应符合指令要求。
数据再利用:在文学写作任务中创造好的回答对于没有专门训练的注释者来说是一个挑战。为了解决这个问题,Qwen2 收集了来自公共领域的高质量文学作品,并利用大模型来制定不同详细程度的指令。这些指令与原始作品配对,作为示范数据。例如,为了生成生动有趣的角色扮演数据,从维基百科这样的知识库中获取详细的人物档案,并指导大模型生成相应的指令和响应。这个过程类似于阅读理解任务,确保了人物档案的完整性得以保持。
Qwen2 收集了一个包含超过 50 万个示例的广泛指令数据集,涵盖了指令遵循、编程、数学、逻辑推理、角色扮演、多语言能力和安全等技能。对模型进行两轮 SFT,序列长度为 32,768。为了优化学习过程,学习率从 7 × 10⁻⁶ 逐渐降低到 7 × 10⁻⁷。为了解决过拟合问题,应用了 0.1 的权重衰减,并将梯度裁剪在最大值 1.0。
RLHF 训练方案包括两个连续的阶段:离线训练和在线训练。在离线训练阶段,使用预编译的偏好数据集 P,通过DPO 来最大化
 关注我们
关注我们