

最近,知名AI助手构建平台Abacus发布了关于如何构建个性化LLM聊天机器人的详细介绍,一起来看看吧!
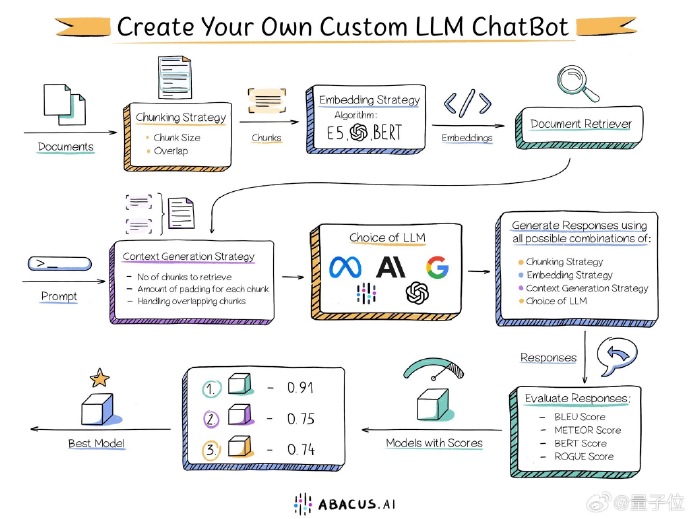
主要可分为8个步骤:
1. 文件处理
使用“分块策略”(Chunking Strategy)把准备好的文件分成文本块(Chunks)。这个策略会帮助你决定每个块的大小和是否有重叠部分等问题。
2. 词嵌入(Embeddings)
将分割好的文本块转化为计算机能理解的向量形式。相关嵌入算法(Embedding Strategy)有E5、BERT等。
3. 文档检索
这些向量会被输入到文档检索器(Document Retriever)里,你可以根据自己的需求搜索相关的信息。
4. 上下文生成策略(Context Generation Strategy)
当用户输入提示词(Prompt)进行查询时,模型需要决定取出多少个文本块来生成上下文,并处理每个块的填充量和重叠部分。
5. 选择大语言模型
你可以选择一个合适的大语言模型(LLM)来生成回答,比如ChatGPT、Claude、Llama、Gemini等。
6. 生成回答
通过组合不同的分块策略、嵌入策略、上下文生成策略和大语言模型,聊天机器人会生成所有可能的回答。
7. 评估和选择最佳模型
你可以用不同的评分标准来评估LLM的回答,比如BLEU分数、METEOR分数、BERT分数和ROGUE分数等。最后,根据得分选择最优的模型来使用。
这样,你就拥有了一个定制化的大语言模型聊天机器人,可以更好地回答一些专业领域的问题。
如果你有一些高质量的私有数据库,或者一些专业的文档资料,非常推荐你试试!
 关注我们
关注我们










