

3D建模进入新时代!微软提出了TRELLIS方法,输入单张图片或文本提示,就能生成3D模型。
先来看一波效果,【视频1】展示了输入文本提示生成3D模型的例子。提示词分别是:
- 采用金色和银色设计的球形机器人;
- 块状、青色机器人,带有橙色铰接肢体。
- 桌子上的未来感机械臂。
【视频2】展示的是输入单张图片生成3D模型,可以看到无论是像带有触须的神龙,还是结构复杂的机甲,TRELLIS都能精准生成3D模型。
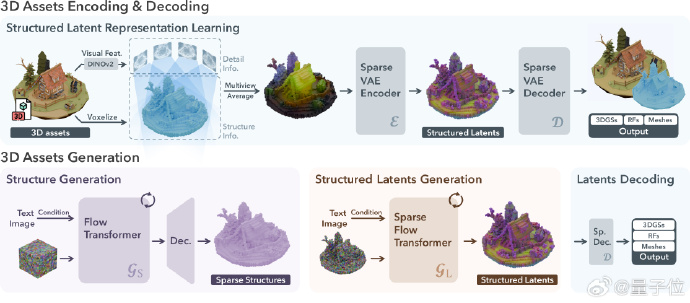
【图3】展示了TRELLIS的原理,图片上半部分:3D资产的编码与解码(3D Assets Encoding & Decoding)
1. 输入3D资产:首先,我们有一个已存在的3D模型(如小木屋、机械结构等)。这个3D资产可来自用户已有的3D数据或数据库中已存在的模型文件。
2. Voxelize(体素化)与多视图特征获取:将3D模型转换为稀疏的体素(voxel)表示,以便在结构化的网格框架中处理。同时,从模型的多个观察视角(多视图)提取视觉特征,使用DINOv2等强大的视觉特征提取器,将不同角度下物体的纹理和形状信息进行整合。
• 多视图特征整合:通过对多个视图图像的细节信息进行汇总和平均融合,不仅能捕捉整体结构,还能保留局部表面纹理与细节。
3. 结构化潜变量的学习(Structured Latent Representation Learning):在获得多视图视觉特征和稀疏体素结构后,系统使用「稀疏VAE编码器(Sparse VAE Encoder)」对这些信息进行编码,得到紧凑、结构化的潜在表示(Structured Latents)。这些潜在变量能高效表示3D物体的整体形态与细微特征。
4. 潜变量解码(Latents Decoding):随后,「稀疏VAE解码器(Sparse VAE Decoder)」从上述潜在表示中还原3D资产。这一步将潜在的隐含表示还原为可观测的3D输出,包括:
• 3DGS(3D Geometry Shapes):直接的3D几何形状表示
• RFs(Radiance Fields):辐射场表示,可进一步用于渲染
• Meshes(网格模型):可被广泛使用的传统3D网格表示
通过这一过程,实现了从已有3D数据到结构化潜在空间再回到真实3D表示的闭环。该闭环为后续基于潜变量的生成和编辑奠定基础。
图片下半部分:3D资产的生成(3D Assets Generation)
1. 结构生成(Structure Generation):给定文本或图像作为条件输入,使用一个「Flow Transformer」或改进的「Rectified Flow Transformer」,来从纯粹的潜在空间中直接生成具有稀疏结构化表示(Sparse Structures)的3D形态。这一步相当于在潜在空间中“生长”出一个全新的3D结构,不需要先有一个具体的3D模型。
2. 从潜变量解码到具体3D模型(Latents Decoding):生成的结构化潜变量(Structured Latents)再通过Sparse VAE Decoder进行解码,从而得到真实的3D形态输出。最终输出的3D结果同样可以是3DGS、RFs或者Meshes。
3. 本地化编辑与控制:由于潜在表示是结构化的,用户还可以对潜在空间进行精确的本地化编辑,调整特定区域的细节、纹理和形状,满足更加细致的创作与设计需求。这意味着在生成后的模型上进行微调时,不必从头训练或修改整个模型,只需在潜在空间中对局部区域加以编辑即可。
通过上述流程,TRELLIS即可从零开始生成多样化的3D模型,并支持对生成结果进行精细化的局部编辑。
此外,TRELLIS在资源有限的设备上也能高效运行,从而大幅降低了3D内容创作的门槛,并提高了3D内容创作的想象空间。
 关注我们
关注我们










